tamuGPT




Overview
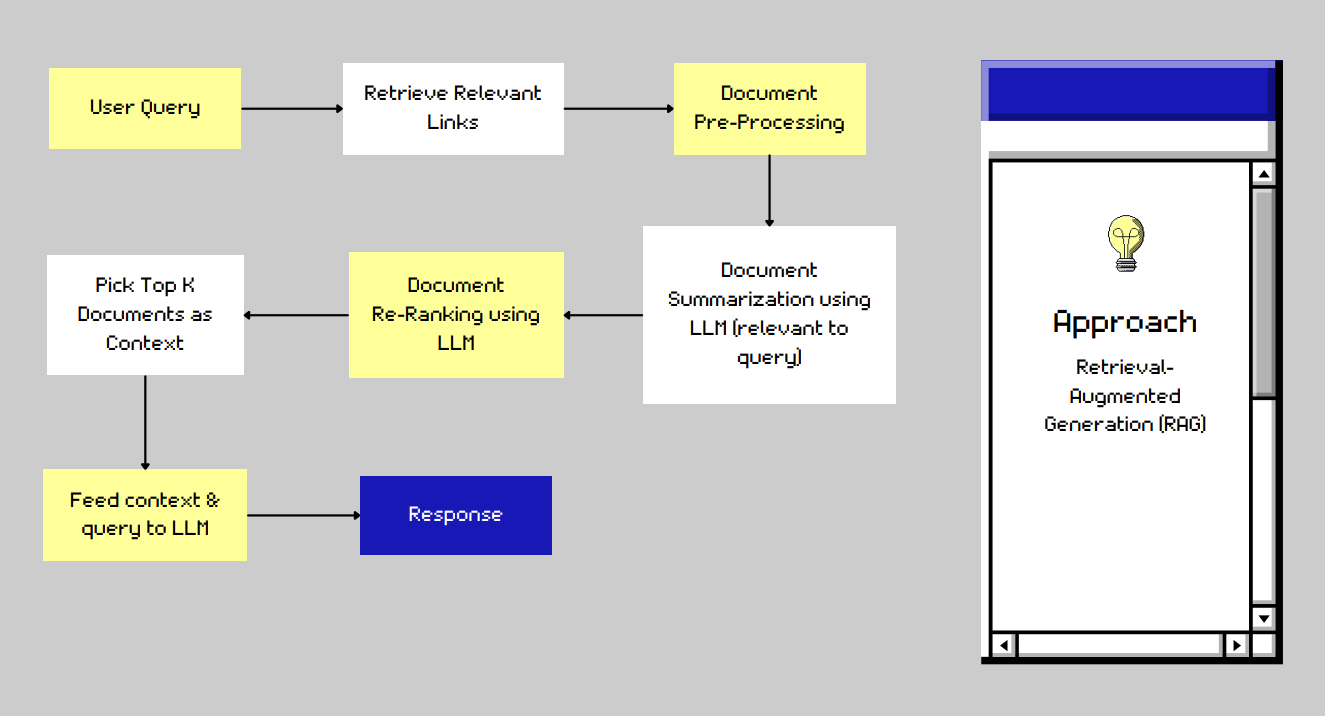
tamuGPT is a sophisticated chatbot from Texas A&M, implemented with Retrieval Augmented Generation (RAG) architecture. A workflow of the model is provided below.
tamuGPT is a sophisticated chatbot from Texas A&M, implemented with Retrieval Augmented Generation (RAG) architecture. A workflow of the model is provided below.